

TL;DR
Longer-running tasks, which are fine to process asynchronously in the background, should not slow down an app. At MaintainX, such tasks include exporting CSV files and generating PDFs. By leveraging AWS Simple Notification Service (SNS) and Simple Queue Service (SQS), we delegate these jobs to several “worker instances” of our app. That way, we can safely and efficiently process such tasks without slowing down our main user-facing app instance.
The Challenge: When Long Tasks Bog Down Your App
Imagine this: MaintainX is running smoothly, users are happily getting on with their maintenance work. Then, a manager requests a massive data export – and bam! The app slows down for all users, preventing them from efficiently doing their work. We don't want that.
Clearly, there's room for improvement. Software tasks that we (and our users) don’t expect to be completed immediately should be done asynchronously so they don’t slow down our app.
We’re talking about tasks like:
- CSV data exports.
- Managing our notification service (check out this article to learn more!).
- Generating and sending scheduled PDF analytics reports.
- Ensuring a secure implementation of our webhooks.
The Solution: Leveraging AWS SNS and SQS for Asynchronous Processing
Our pick for a straightforward solution is to send asynchronous tasks over to separate “worker instances” of MaintainX using Amazon SQS and SNS.
Amazon SNS (Simple Notification Service) acts as a publisher/subscriber broker – think of it as a smart messenger that can take a message and deliver copies to any number of interested parties. When our backend publishes a message to SNS, it doesn't need to know who's listening; it just sends the message and continues with its work. Amazon SQS (Simple Queue Service), on the other hand, acts as a reliable message queue, storing messages until they can be processed. It's like a buffer that ensures no task gets lost: if our system crashes, the messages are still there waiting to be processed when we're back up. If we get a sudden flood of tasks, SQS queues them up so they can be handled at a manageable pace.
But what are those “worker instances” that consume messages from SQS? Essentially, they’re separate instances of our backend that process only the asynchronous tasks. By having the main instance delegate longer-running tasks to such worker instances, we avoid slowing down the main instance that users interact with directly.
Worker instances contain only the backend modules needed to run asynchronous tasks. We’ll refer to this subset of modules as the “worker-api”. To help ensure fast processing, we use a minimum of 4 worker-api instances, and can dynamically scale to up to 20 instances to satisfy periods of high demand.
This event-driven approach provides several advantages: it's highly scalable, future-proofs our architecture, and ensures higher fault tolerance. We've found it to be super useful for keeping our app snappy and reliable. So without further ado, let's take a look at how it works!
How Event-Driven Asynchronous Processing Works
When a user triggers an asynchronous job on MaintainX, we publish a message containing the job's payload to an Amazon SNS topic. SNS allows us to send notifications containing the message to other AWS services. In our case, these messages are sent to an Amazon SQS queue which is polled by several worker instances for processing.
With these details in mind, let's illustrate with an example:
- A user triggers an asynchronous job. They request a CSV export of the asset status history of the asset with ID 47.
- The message is sent to the worker-api SNS topic with a payload of { assetId: 47 }, and the message's type, ExportAssetStatusHistory.
- The worker-api SNS topic routes the message to the worker-api SQS queue.
- All worker-api instances continuously poll this SQS queue for new messages.
- As soon as a worker-api instance is free to take on the job, it uses the message's type and payload to know which processor function to call, and what inputs to call it with.
- As the export is processed, the worker publishes the progress and eventually the final URL to Redis, with the file itself stored in an AWS S3 bucket.
When the export begins, the frontend triggers a GraphQL subscription request. The GraphQL subscriptions API then receives this request and establishes a websocket connection to maintain communication.
In turn, this API listens to the Redis pub/sub events so that it can forward them to the appropriate websocket.
That way, the frontend is constantly aware of the export's progress, and once the URL is ready, it can update to present the download URL to the user.
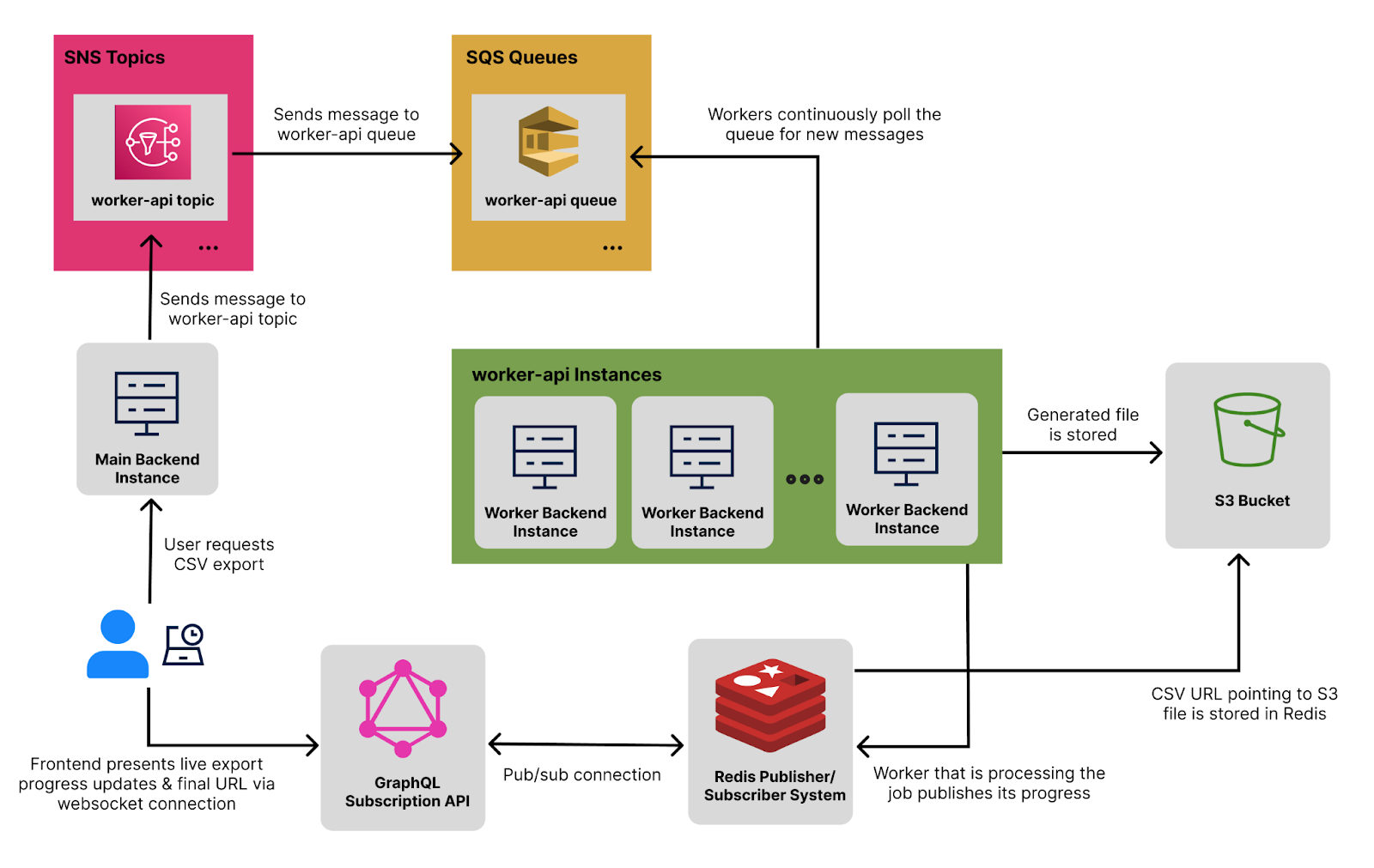
Caption: A high-level overview of an asynchronous CSV export being processed.
But what if something goes wrong while processing a job? By storing copies of messages in a DynamoDB database table, we can inspect message types and their payloads for debugging purposes. It’s a lot of data to store, so we’ve configured a time-to-live (TTL) period of two weeks on the database. Any data older than two weeks gets deleted automatically.
Additionally, SQS enables automated retries of failed jobs. If a job keeps failing after several retries—which often happens with so-called “poison pill” messages that simply can’t be processed—the message is stored in what’s called a Dead Letter Queue (DLQ). When we fix the issue that prevented the system from processing such messages, we can then trigger a rerun of the messages stored in the DLQ to ensure that all jobs get processed.
Future-Proofing Our Architecture: The SNS-SQS Combo
At first glance, it might seem odd that we need to send messages to an SNS topic which immediately forwards the message to the corresponding SQS queue. Why not send messages straight to the queue?
Because there's no additional cost to having SNS push to AWS services, there's no drawback to our starting to use it now. And combining SNS with SQS makes our setup more future-proof: if we need to, we can eventually add more than one subscriber per SNS topic.
One interesting use-case for this is to facilitate switching between different versions of our worker-api. For example, if we find a faster way to export asset status history, we can set up two SQS queues for that SNS topic. One queue gets polled by the old worker, and the other by the new worker.
Then, we can gradually transition the processing of new messages from one queue to the other. Once the transition is complete, we can remove the original queue and worker. Smooth transitions all the way!
Why This Approach Works So Well
As you can see, this setup provides tons of benefits. For one, it makes any app much more scalable. Regardless of the volume of asynchronous requests, the worker instances reliably process them at their own pace and the main instance that users interact with doesn’t slow down.
Additionally, the system has high fault tolerance thanks to SQS's at-least-once processing guarantee (stay tuned for a future post about messaging patterns and guarantees!), task persistence in queues, automated retries, Dead Letter Queues, and even our DynamoDB setup.
The Fine Print
For all of its benefits, this approach comes with a few costs.
First, jobs are processed at a higher latency. But because this setup is meant exclusively for asynchronous jobs, increased latency is not an issue.
A more significant drawback is that it increases the solution’s complexity and makes it more difficult to debug. As a result, we need more onboarding and quality documentation to help engineers understand what’s going on. All of this also requires additional monitoring and logging, further increasing associated engineering efforts.
Wrapping Up
We hope this post has provided you with a solid understanding of how to better handle asynchronous tasks in any app. By leveraging SNS and SQS, you can significantly improve your application's performance and user experience, just as we've done at MaintainX.
The key benefits of this event-driven approach include:
- Improved scalability.
- Increased fault tolerance.
- Better user experience with responsive app interfaces.
- A more future-proof architecture.
While implementing this solution requires some initial setup and increases overall complexity, the long-term benefits of application performance and maintainability make it well worth the effort. Whether you're dealing with data exports, report generations, or any other time-consuming tasks, this setup can help keep your application responsive and your users happy.
If you found this useful, be sure to drop your email below to ensure you get our next engineering blog posts!

Yann Bonzom is a software developer at MaintainX.


.webp)
.webp)