

TL;DR Migrating to microservices is a big technical challenge, but it’s an organizational one too. Getting buy-in and evolving your engineering culture are as important as nailing the architecture. Here’s how we did it at MaintainX.
I tried to get to work the other morning and it was a pain. I got to the nearest bike share rack, and it was empty. Subway it is then. Darn it, there’s a problem on the tracks so it’s out of service for the next hour. I guess I could drive or take a taxi? But with other transit options down, there’ll be more traffic on the road. And I’ll be late to my first meeting.
How did we get to this point?
Funny enough, my first meeting that day was a demo of our proof of concept for the first service running outside our monolith. It got me thinking. An HTTP request coming into a growing monolithic software application would probably feel exactly the same way I did.
As a city expands, traffic congestion increases, slowing down everyone’s commute. Essential services become delayed, and residents often find themselves stumbling over one another in crowded streets, making coordination and progress increasingly difficult. Software monoliths usually have the exact same problems as they grow.
Fortunately, it’s easier to change software than it is to change a city, and one way to do that is to start migrating gradually to microservices.
But, how can one navigate transitioning out of a monolith safely, steering clear of potential roadblocks and delays, all while appreciating “the true horror, pain, and suffering” (Sam Newman - 2015) that often accompany running microservices in production?
Chipping away at a monolith is never an easy task. The slow migration to microservices is literally an art form. But I’ll try to explain how we started that journey at MaintainX as we built our new User Notifications service, and share the details of the decisions that led to our current architecture. So, buckle up as we embark on a quest to liberate our code from the shackles of stagnation and embrace the complexity and scalability of a small number of microservices.
The “Good” Beginning 📖
The Winning Feature 🔔
We chose User Notifications as the proof of concept feature for distributing our monolith. Many factors contributed to this selection. Firstly, it addressed a critical gap in our system: we had user notifications in place, but no notification settings for users to control what they want to receive. This presented an opportunity for us to enhance that aspect incrementally.
Moreover, user notifications are a good fit for asynchronous event-driven models. They need a minimal distributed state to function. And because events are often considered to be simple state transfer notifications between services that represent facts about something that happened in the past, they’re well-suited for a microservices architecture. So there was a good synergy between the feature and the architectural shift we wanted to make.
Beyond its technical suitability, the feature caught my personal interest. At MaintainX, we foster a "We accept PRs" culture, encouraging anyone to contribute fixes or enhancements. And boy do I love events!
This combination of product fit, technical alignment, and personal interest made a strong argument for the User Notifications feature to take the spotlight in our proof of concept.
The Requirements 📋
I get it, requirements often seem as thrilling as watching paint dry, and they have a pesky habit of shape-shifting just when your team gets into its groove, velocity wise. On the other hand, they are the thread guiding you through the labyrinth of your project. Without it, you're just wandering aimlessly and are likely to lose your way (i.e., not reach your objective).
These were our high-level requirements:
- Feature Parity 🔄
We asked ourselves, "Should our shiny, new User Notifications feature be a twin of its monolithic sibling?" Absolutely! Feature parity helps smooth the transition, keeping users happy with the notification experience they’re used to. It also ensures you’re providing product value, and not accidentally removing it. - User-Controlled Settings ⚙️
Questions about the granularity of settings danced in our heads. Should we provide control over push and email notifications of interest? What about muting? Would @mentions bother user’s coworkers too much? Ultimately, we decided that as a stretch goal, we wanted to replicate Discord’s level of granularity over user notification controls. - Event-Driven Architecture 💌
To shift towards a microservices architecture, we knew that asynchronous communication was key. User notifications are an ideal fit for an event-driven model, so we needed to articulate the requirements for an efficient eventing system. This included determining what types of events to trigger and what information to communicate, as well as shopping for an event bus to get that information flowing. - Scalability and Performance 🚀
Anticipating future growth, we delved into the scalability requirements of the User Notifications service. Questions arose about how the system would handle an increasing volume of notifications and users. We considered factors such as queue throughput, instance auto scaling, segregation of reads and writes, and overall latency. Our goal was to ensure the microservices architecture could accommodate the evolving demands of our user base.
The Shopping Experience 🛒
With overall requirements in mind, and a hazy vision of where we wanted to go, we started shopping for our main eventing technology. We wanted to find a black box that could gracefully handle incoming and outgoing events. The shopping process unfolded like this:
- Create a set of criteria to compare technologies: I won't bore you with the exhaustive list, but our criteria included considerations like pricing, event replay, retention, schema management, and various security features.
- Compile a list of technologies to evaluate: No deep-dives at this stage. If it handled events, it made the list.
- Extract metrics from the current production environment and devise test scenarios: For instance, we extracted the volume of write transactions and amount of data written to our database monthly, and looked at how it had evolved over the past year. This formed the basis for potential future scenarios, which we used to evaluate the cost of each solution.
- Evaluate each technology solution: Having a well-defined set of criteria and common scenarios enabled us to distribute the evaluation tasks to multiple developers, and still get results that we could compare fairly.
- Create an Architecture Decision Record (ADR): Document the final choice to provide context for colleagues, future developers within the company, or even our future selves questioning past decisions.
After completing this entire process, a combination of AWS Simple Notification Service (SNS) and AWS Simple Queue Service (SQS) ranked highest based on our requirements, so that’s what we chose. Did it tick all the boxes? Certainly not. But the cost of implementation for a proof of concept was relatively low. And we also knew that if we ever needed to migrate to another eventing technology, SNS would make that migration relatively painless. For perspective, we haven’t migrated to something else yet, and to this day, running with millions of events per month, this technology combination still only costs us the price of a couple candy bars a month.
The “Eternal” Design Revision 🔄
Technical Design is, in our opinion, one of the most important parts of any new project. But it’s important to understand that your design is never set in stone.
I'd like to share the unedited design diagrams we drew almost two years ago when we started this project. They’re not particularly sophisticated, but I believe these raw sketches offer a glimpse into our design journey, and show how an iterative approach can elevate simple ideas to the level of maturity expected in production.
Here’s the very first diagram for the user notification service’s architecture design:

There was nothing impressive about this iteration. Our goal was simply to send events from our monolithic service and react to them on the other side in our new separate service.
The SNS and SQS Division
In our next design evolution, AWS SNS acts as a Publisher/Subscriber broker. We abstract the subscriber (in this case, the User Notifications service) from the publisher (the monolithic backend). This decoupling allows the backend to produce events without needing to know who's on the receiving end. It can simply dispatch events and proceed with its operations.
Over time, the SNS service can be used as a message duplicator. It receives a message on one side and sends duplicate copies to all interested parties. For example, said parties could be an AWS Lambda, another service, or even a future broker technology we could migrate to.
One noteworthy potential consumer is AWS SQS, functioning as a message queue to persistently store messages until the service consumes them. It essentially acts as a buffer for your service. Had a crash in production? No problem, just pick up where you left off. Have a huge spike of messages coming in? We got you! Just consume them at your normal rhythm. Or, if you want to shorten the latency, spawn more instances to help tackle the workload.
The diagram below illustrates our initial intent to use SNS as an inflection point for future scalability:
—
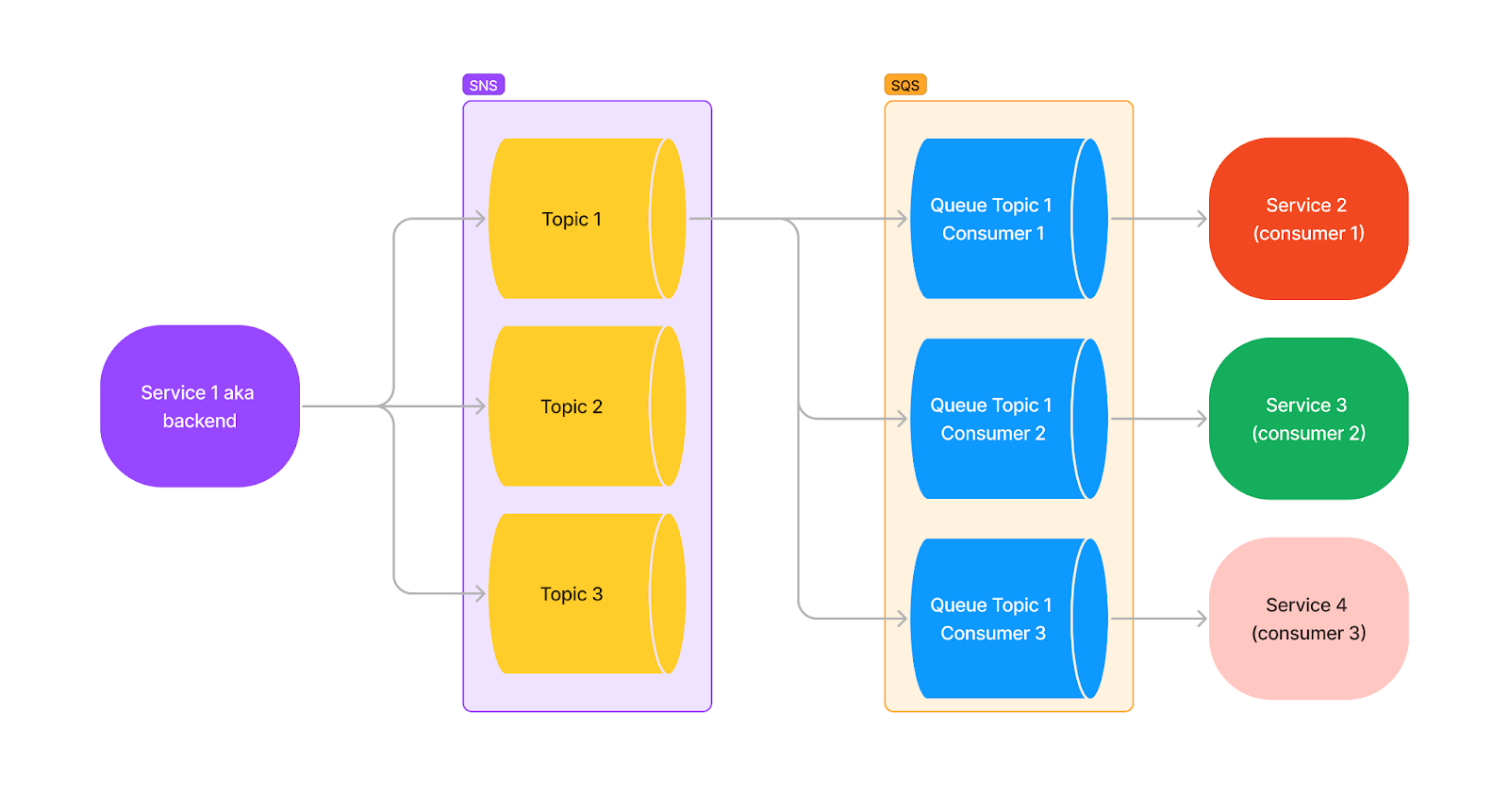
It gets more interesting in the next diagram, which shows how we can apply this way of using these technologies in our expected infrastructure:
Looking back at it, this is the exact point where our current system architecture was born. We had one topic for each domain needed by the notification feature, but importantly, we also had one queue for each of those domains. We also realized that we had overcomplicated the design by unnecessarily attempting to replicate Kafka's commit log with one persisted queue per topic. Recognizing this, we simplified the architecture in the next iteration to reduce cost and complexity.
The Queue Aggregation
The diagram below reflects our optimization. We consolidated events into a single queue for each service that subscribes to events:

In the context of the user notification service, this change simplified the overall architecture and reduced implementation complexity. We also maintained horizontal scalability, even though we had only one queue, thanks to the partitioning abilities of SQS.
The Near-Infinite Scalability
One last problem needed to be resolved: ordering and delivery guarantees for messages. Some messages required guaranteed ordering and at-least-once delivery to accurately replicate part of our MySQL database state in DynamoDB. For other messages, order was not significant, and dropping them wouldn't result in catastrophic failures or state corruption.
Enter AWS's first in, first out (FIFO) mechanism, a double-edge sword. It gives us both ordering and at-least-once delivery guarantees within SNS topics and SQS queues. But it’s more costly in terms of performance and scalability, and has fewer features compared to standard topics and queues. Armed with this solution, we made a subtle yet impactful optimization depicted in the diagram below:

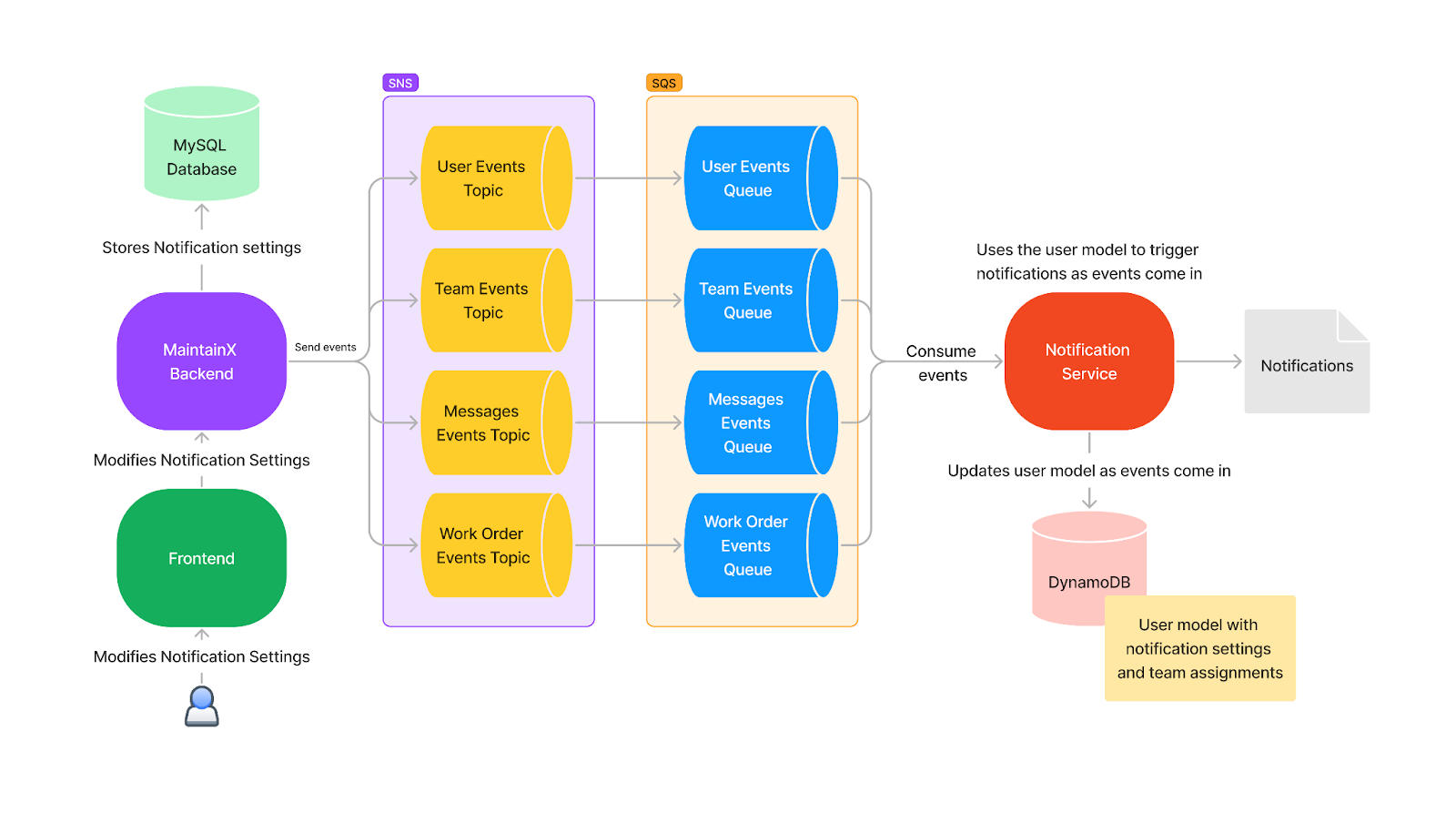
This design iteration is still representative of our user notification infrastructure, albeit with additional topics and services nowadays.
Here we introduced a clear distinction between standard topics/queues and their FIFO counterparts. Keen-eyed readers might notice a bifurcation in the service itself. We realized that the FIFO constraint applied exclusively to certain events, and the anticipated volume of those events in production was significantly lower than others. It made little sense to subject both groups of events to identical scaling levels.
Separating our state events and our triggering events allowed us to control their scalability independently.
- State events are changes in the backend entities—such as updates to Users, Conversations, Teams, Settings, or Organizations—that need to be replicated in DynamoDB.
- Triggering events, on the other hand, are specific occurrences or actions that necessitate checking the state to decide whether a notification should be sent to a user.
What excited us the most was that removing FIFO constraints on the components that handle triggering events translated to near infinite scalability for sending notifications. Was that scalability needed now? Hell no! But it was easy to justify in the name of future-proofing our system for unforeseen demands.
The Buy-in from Leadership 👑
Remember when I said technical design was one of the most important parts of any new project? It is. But no matter where you work, the most important part of any project is getting buy-in from leadership. You can have the best architecture design, the finest technology choices, and the most experienced team of developers, but without management's approval, your project can sputter and fail to take-off.
So how do you get buy in?
There’s no recipe for this, but I think it boils down to generating excitement by demonstrating the substantial product value you’ll get by executing the project. Product value can come from multiple sources such as adding new features, solving problems that impact customers, or even just maintaining proper operations as you add more users (which was the case for us).
Since we don’t yet live in a dystopian future and your management team is still made up of human beings, it tends to be easier to generate excitement and communicate the vision of your project by creating a tangible proof of concept. Showing a working feature or technical achievement in a short time builds confidence in your project, however hacked together it might be. It comes with the added benefits of forcing you to clearly define where you intend to go, and gives stakeholders the opportunity to provide feedback.
And as a matter of fact, that’s exactly what we did:
- We created our designs and selected our technology.
- The third iteration of the design was used in a kickoff meeting to align everybody’s vision and collect early feedback from leadership.
- We implemented an initial proof of concept of the service. It was far from production ready, and supported only one type of user notification for one specific scenario.
- A demo got us approval to proceed further and harden the service to make it production ready.
- We implemented the rest of the planned user notification features.
- Just over a month in, the new service was ready to go into production with a limited rollout to select customers.
- We spent several more weeks testing and fine tuning before making the service generally available.
Ultimately, this entire process helped us demonstrate to our product team that our project offered both technical and product value. We proved that we could offload some work from our monolith while simultaneously adding new notification features that customers had long been requesting.
The (Bad?) Implementation 💻
This is it. The last step of our proof of concept. Implementation is usually either the best or worst part of a project depending on the current state of the system.
There are a couple scenarios that can make implementation painful:
- Working on poorly designed legacy code with a lot of technical debt.
- Missing or outdated documentation on code you have to refactor.
- Lack of tooling to enhance the development experience.
- Unclear or changing implementation requirements.
In our case, implementation was the best part of our project, with design being a close second. We relied on feature flags to avoid affecting our legacy code. Tooling wasn’t much of an issue either since working on a clean slate meant we could basically build the tooling that felt necessary to us. For the rest, being well prepared is key to enjoying this part of the process. Of course, even during implementation, you should follow a proper game plan.
Game Plan:
- Create an abstraction point in the monolith: Our first strategic move was to establish a bridge between the old and new paths within the monolith. By encapsulating the new code behind a feature flag, we gained the flexibility to toggle new behaviors on and off while simultaneously disabling the old ones. This abstraction point gave us a very smooth transition process.
- Set up the eventing infrastructure: Setting up the necessary eventing infrastructure was pivotal. This step involved configuring the environments to deploy our defined SNS topics, the SQS queues, and the subscription necessary to push events from one to the other.
- Add SNS publishing to the backend: We leveraged the abstractions we'd made so far to make entity state changes produce their corresponding events once our feature flag was toggled. This happened whether or not they triggered notifications. All of this was done using the SNS SDK with our own wrapping layer over it.
- Create the new service: This was a significant milestone. It was the first time we had hosted resources running outside our monolith. The service came complete with its own repository and continuous integration (CI) pipeline. It was designed to accommodate our evolving architecture and seamlessly transition notification features out of the monolith.
- Implement the old features in the new service: Migrating features from the monolith to the new service was a painstaking process. We carefully implemented each feature in the new environment to ensure a seamless transition.
Building Essential Tooling:
To complement our implementation efforts, we built essential tooling that played a critical role in different facets of the development lifecycle:
- Local development experience: Driving developer adoption internally is paramount. Guided by the InnerSource principle, we invested in a smooth and efficient local development experience to entice developers to contribute, and ease implementation efforts.
We wrote a comprehensive README that included:
- The project’s maintainers.
- Requirements.
- Instructions for contributing.
We also detailed the architecture from a User Notifications service perspective along with a diagram that helped developers quickly understand the service’s role. Additionally, we developed tools that enable the deployment of essential cloud infrastructure with a single command. These tools offer commands for debugging potential issues, which streamline the development experience.
- Feature management in production: We cheated a bit on this one. A management dashboard for each environment was already available for us to configure feature flags on a per-tenant basis. We highly recommend building or buying such a solution for yourself.
- Production monitoring: Do not skimp on this step.There is nothing worse than having no visibility over something that goes wrong in production. Proper monitoring provides real-time insights into the performance and health of your production environment. That’s why we crafted a detailed dashboard before enabling the feature flag for anyone in production.
The dashboard showed essential metrics and logs, providing us with vital information about the service's status. On top of that, we made sure we got notified if any metrics went out of expected bounds so we could take appropriate action. - Debugging in production: One big lesson we learned here is that tools for debugging new services are very important and you should not wait for your service to be generally available to work on them. We experienced that the hard way.
After handling cases from countless customers who expected to receive (or not) notifications, we developed a tool to log recent decisions about why a user was notified (or not), and what the user’s settings were at the time of the decision. This increased visibility into potential bugs affecting our service in production, and saved us a considerable amount of engineering time. By empowering our support team to manage these issues, we streamlined the troubleshooting process and improved overall efficiency.
This comprehensive approach to implementation, coupled with the development of purpose-built tooling, laid the groundwork for a successful proof of concept to demonstrate the value and feasibility of our first event-driven service. The journey was not without its challenges, but each step brought us closer to a more scalable, resilient, and maintainable system.
And the “Ugly” Production Migration ⛔
Taking inspiration from Sam Newman's wisdom of gradually turning the stereo dial, our production migration process resembled a subtle low-volume melody steadily gaining intensity. We understood the significance of small, incremental steps to ensure a seamless transition and minimize potential disruptions.
- Feature flag deployment:
Initially, the new service remained hidden behind a feature flag, which allowed us to control activation and easily revert to the old path if needed. This phase enabled us to deploy the service in a controlled manner, exposing it only to a subset of developers or internal stakeholders in the production environment.
Here are some interesting statistics that highlight the power of these capabilities.- 108 is the number of times we deployed our monolith to production throughout the development process.
- 137 is the number of times the notification service was deployed to production in that timeframe.
All this was achieved without ever disrupting usual operations or the existing notification system. If that isn’t a testament to efficiency, I don’t know what is.
- Limited alpha user rollout:
Slowly, we toggled the feature on for select customers, and monitored it closely for any anomalies or unexpected behavior. Limited user rollouts allowed us to gather valuable data on real-world usage and identify most major issues that we might have overlooked in testing. - Iterative bug fixes and enhancements:
As issues surfaced, our team addressed them promptly, leveraging the feature flag to make quick adjustments without affecting the entire user base. This iterative approach was key to a painless migration in production. - Beta feature enablement:
With increasing confidence in the new service, we selectively enabled our new notification features for more users, which allowed us to monitor the impact on performance and user experience. We rolled it out to our 150 biggest enterprise customers in order to gather better volumetric data about how the service would react. We carried this out in a single week before enabling the features for all Beta customers. - Full production deployment:
After thoroughly testing, monitoring, and addressing issues, we finally reached the point of full production deployment. Pressing that button is pretty intense. Spoiler alert, we still found lots of additional issues to fix which required us to develop debugging tools. Production is always wilder than you think it’s going to be, and it can be pretty hard to replicate the volume and randomness of it. - Continuous monitoring and optimization:
Even after full deployment, the journey never ends. The monitoring dashboard still gets decent mileage and we’re still adding alerts as we discover new potential problems.
The End 🔚
In embracing the “ugly” aspects of production migration, we recognized that the path to improvement often involves incremental, data-driven iterations. The iterative deployment strategy not only allowed us to deliver a more robust and reliable notification service but also fostered a culture of adaptability and continuous improvement within our development team. Looking back on it all, pushing the proof of concept all the way to production had to be the hardest part of it all.
As we navigated through the intricacies of microservices architecture and event-driven patterns, we discovered that the journey is as important as the destination. Our experiences, failures and successes during this entire project shaped not just our software, but also our team dynamics and resilience.
This left us with a good key learning though: It's not about getting everything right, it's about getting started and making progress. Remember, in the world of software development, the dial is never fixed, the architecture is never static. It's a dynamic process, a continuous journey toward improvement. So, keep iterating, keep adapting, and most importantly, keep shipping. The “ugly” may not always be avoidable, but with the right mindset, it can be the catalyst for the most beautiful transformations. Cheers to the journey, the lessons learned, and the better systems yet to come! 🚀✨

Mathieu Bélanger is a Technical Lead Software Developer at MaintainX with nearly a decade of experience designing and implementing distributed software. He’s really passionate about home automation and IIOT. Mentioning subjects like event sourcing or event-driven architecture can also make him talk for hours. Fun fact, he has its own server rack at home to manage his infrastructure.


.webp)

.webp)