With downtime costs ranging from $25,000 to $500,000 per hour, equipment failure isn’t just an inconvenience—it’s a major financial hit. For facilities managing complex operations, every minute of idle equipment disrupts workflows and eats into profits. That’s why closely monitoring maintenance metrics is crucial. Tracking the right data allows you to spot potential issues early, address problems on time, and optimize your resources.
Among maintenance metrics, system availability is a key measure of operational effectiveness. Monitoring system availability provides valuable insights into your equipment reliability and readiness. It also helps ensure that your assets are available for production when you need them. Focusing on this metric can strengthen your maintenance planning and help you shift from reactive to preventive maintenance.
In this article, we explore what system availability means, how to calculate it, and the best strategies for improving it.
What is system availability?
System availability is a maintenance metric that measures the percentage of time an asset can be used for production. It calculates the probability that a system won’t experience downtime when workers need to use it.
Also referred to as equipment or asset availability, it is an essential metric for organizations that depend on complex equipment to function.
Manufacturers, warehousers, and oil/gas providers are some of the providers most likely to track this key performance indicator (KPI).
When is an asset available?
An asset or system must meet the following three qualifications to be considered available:
- Functionality: It is not out-of-service for inspection or repair work.
- Normalcy: It runs in an ideal setting at an expected rate.
- Availability: It is available for use without disrupting production schedules.
In other words, system availability quantifies the probability that, for example, your most integral forklifts, conveyor belts, and HVAC units are in good working condition and are not prone to outages.
“World-class maintenance is not just about the maintenance practices of the maintenance organization in a vacuum. It is about the way the entire organization uses all the means at its disposal to protect its ability to produce exceptional value for its customers. It is a journey, not a destination—a process, not a product.”—Reliable Plant
How to calculate system availability
System availability is expressed as a percentage of the actual operation time divided by the total amount of observational time. In other words, it’s the total asset uptime divided by the sum of the total amount of uptime and downtime. Higher availability, which translates to lower failure rates, means fewer system failures and less corrective action.
System availability formula
System availability = uptime / (uptime + downtime) * 100
Or, put another way,
System availability = (Actual operation time in hours / Total time in hours) * 100
Example:
A conveyor belt in a factory was observed for 10 hours in one day. During that time, it broke down, and the total downtime was two hours. The system availability for the conveyor belt is:
- (Actual operation time in hours / Total time in hours) * 100
- (8 hours / 10 hours) × 100
- System availability = 80%
While 80% is a good number, it falls short of the ideal threshold. Reliable Plant reports that experts consider “world-class system availability” to be a minimum of 90 percent.
Alternative system availability formula
An alternative route is to use the maintenance metrics Mean Time Between Failure (MTBF) and Mean Time to Repair (MTTR) to arrive at your availability calculation.
Both MTBF and MTTR reveal the effects of breakdowns on asset operational times. MTBF describes the period when an asset is performing under good working conditions. MTTR, on the other hand, refers to the amount of time it takes to repair an asset.
Use the following formula to calculate availability:
System availability = MTBF / (MTBF + MTR)
Ultimately, the formula you use to measure system availability is a matter of personal preference.
What causes systems to fail?
In general, system failures are often the result of a combination of factors. Some of the most common factors include:
Poor or irregular maintenance: If you don’t regularly check and service your machinery and equipment, minor issues can escalate into major problems, leading to unexpected downtime and costly repairs.
In addition, improper maintenance can also lead to failure. Carrying out regular maintenance work but not performing the tasks properly still leaves you at risk. From one angle, it’s even worse, as you’ll spend time and resources on maintenance tasks that yield no results.
Improper use: Another frequent cause of system failure is improperly using or operating the equipment. Whether due to inadequate training or simply not following the recommended guidelines, using machinery wrongly can increase the likelihood of breakdowns and shorten its lifespan.
External factors: Environmental conditions, such as extreme temperatures, humidity, or exposure to corrosive substances, can damage equipment.
Lack of spare parts: Not having critical spare parts readily available can delay repairs, extending downtime and impacting system performance.
Poor quality parts: Manufacturing defects can result in parts or components that are prone to failure under stress.
Aging equipment: Older or poorly maintained machines are more prone to frequent breakdowns and extended repairs, significantly reducing system availability.
Why tracking system availability matters
Maintenance managers rely on system availability metrics to determine how well their existing maintenance strategies are working. It’s a good way to gauge if your current maintenance activities and schedules are maintaining uptime or not.
Tracking system availability also helps you build system reliability. You’ll be able to identify trends and patterns in downtime. Understanding when and why systems fail lets you pinpoint weaknesses in your equipment or maintenance processes, enabling you to proactively address them.
Importantly, system availability also helps organizations gain insight into their profitability. The amount of time a critical asset remains operational is directly proportional to facility output and performance. For example, downtime costs automobile manufacturers an estimated $50,000 per minute or $3 million per hour. While most industries lose considerably less, the average is still tens of thousands of dollars per hour.
How to track system availability
Given the different ways to calculate it, and all the factors involved, keeping track of system availability can be a complex task. However, this is another area where the right tools can streamline the process. Imagine, for example, using a computerized maintenance management system (CMMS) that enables you to easily track and calculate metrics like downtime, MTBF, and MTTR. Half your work is done already.
By using a CMMS, particularly one that’s integrated with meters, you can automatically collect real-time data on equipment usage, performance, and health. This continuous monitoring allows you to immediately detect anomalies, enabling your maintenance team to respond quickly and prevent minor issues from escalating into significant failures.
In addition, a CMMS makes it easier for you to manage and track maintenance work in your facility. You can create and assign work orders to technicians who will receive them directly on their mobile devices, log their activities in real-time, and update the system immediately after completing a task. This process ensures you maintain accurate and up-to-date records of downtime, repairs, and inspections. By having all this information readily available, you can better analyze your key metrics, identify trends, and implement preventive maintenance strategies to improve overall system availability and reliability.
5 ways to improve system availability
As previously mentioned, the more uptime your team experiences, the better your company’s bottom line. Here are three simple ways to improve system availability:
1. Optimize your preventive maintenance program
A well-tuned preventive maintenance plan can catch small issues before they escalate into costly failures. Routine maintenance, like regular inspections and scheduled repairs, will reduce the risk of unexpected breakdowns. By implementing this, you’ll ensure your equipment is available when you need it most.
Read: What Is Preventive Maintenance? The Beginner’s Guide to Running PMs to learn more.
2. Automate work orders
Automating the creation and assignment of work orders eliminates manual delays and ensures your team can address maintenance tasks promptly. This speeds up response times and keeps your system operating efficiently by preventing unplanned downtime. One way to simplify this process is to use software solutions with work order management features. For example, MaintainX allows you to schedule work orders in advance and trigger condition-based maintenance.
3. Use short codes
Implementing standardized short codes for frequent issues simplifies reporting and communication between teams. Maintenance staff can more efficiently diagnose and resolve problems by using quick, easy-to-understand codes, boosting overall system availability.
This is another process you can simplify with the right software. A computerized maintenance management system (CMMS) like MaintainX, for example, can help you easily catalog these codes. Each abbreviation code should describe a typical equipment issue, cause of failure, and remedy. For example, you might describe an air leak as ARLK.
Failure codes ensure all team members are on the same page when documenting both equipment issues and resolutions in data management platforms. This approach helps teams easily find data when conducting a Failure Mode and Effects Analysis (FMEA) or Root Cause Analysis. For example, when sorting through a filtered short-code search for ARLK, managers can easily see which assets have broken down because of an air leak.
Organizations can develop specific codes, but those with stringent tracking requirements should consult standardized codes generated by regulatory bodies.
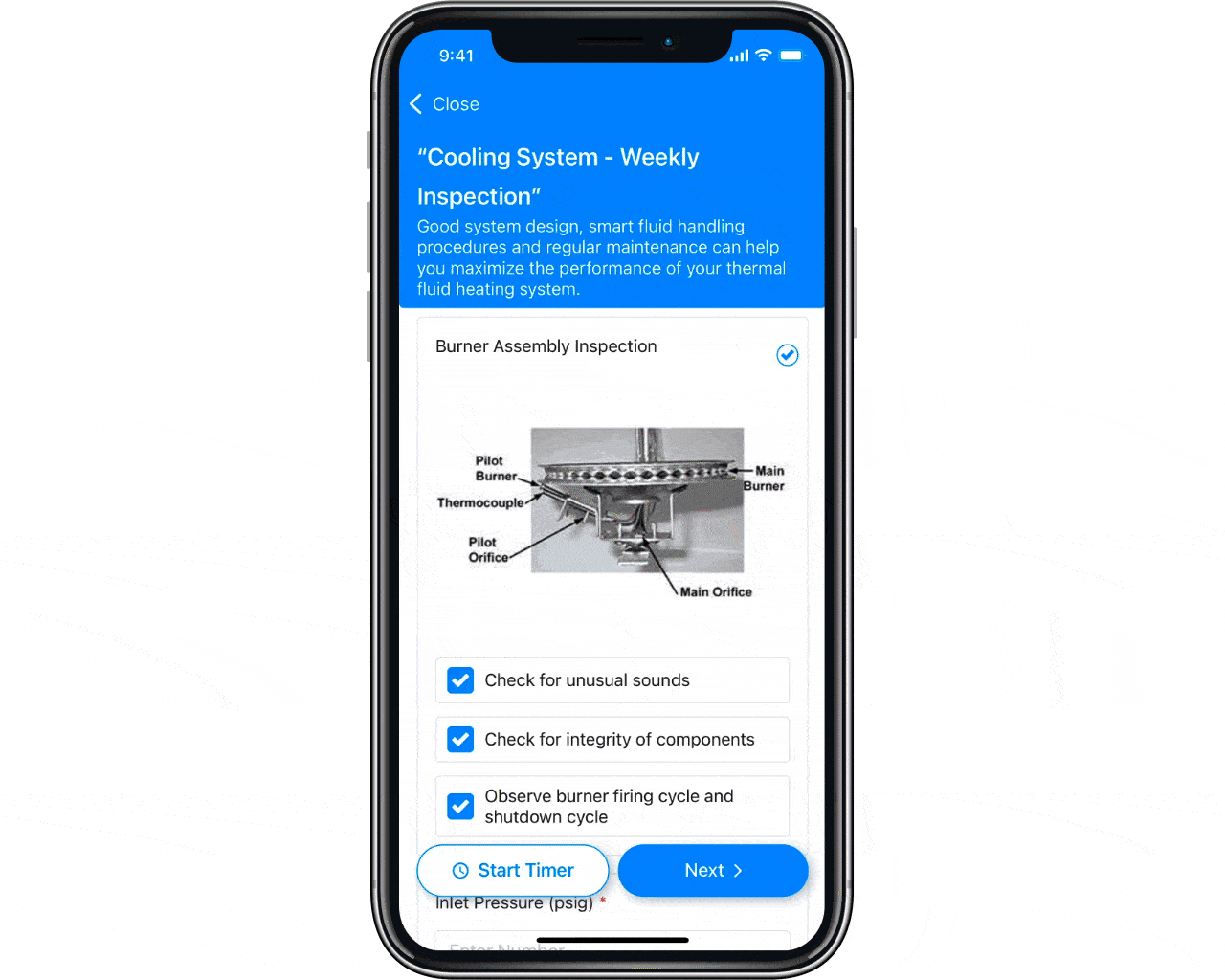
4. Streamline Standard Operating Procedures (SOPs)
Clear, consistent SOPs reduce confusion and ensure workers can complete tasks accurately and efficiently. With the right tools, you can create SOPs and digital checklists that guide your staff step-by-step through specific tasks, minimizing errors and downtime. For example, MaintainX allows you to create SOPs from scratch or edit pre-built templates tailored to your needs. You can also use MaintainX’s AI-enabled Procedure Generator to automatically generate SOPs based on your prompts.
Read: 8 Tips for Developing Standard Operating Procedures (That Get Used) to learn more.
5. Keep spare parts on hand
Keeping an organized inventory of critical spare parts minimizes delays when failures happen. By ensuring the right parts are on hand, your maintenance team can complete repairs quickly, reducing downtime and keeping systems running smoothly. This simple step directly boosts system availability by avoiding extended wait times for parts delivery.
Improve system availability with MaintainX
Increased system availability leads to improved efficiency, higher production levels, and healthier business margins. MaintainX’s robust CMMS offers an intuitive, easy-to-use platform that helps you improve system availability by reducing downtime, streamlining work order management, analyzing your metrics, and more. Take advantage of features like:
Anomaly detection
MaintainX helps you immediately identify when you’re working with numbers that seem irregular or abnormal. With AI-powered anomaly detection, MaintainX’s system uses historical data to automatically determine whether a value that a user enters in a procedure or a meter reading is an anomaly. Anomaly detection helps you predict faults, eliminate errors, and minimize downtime.
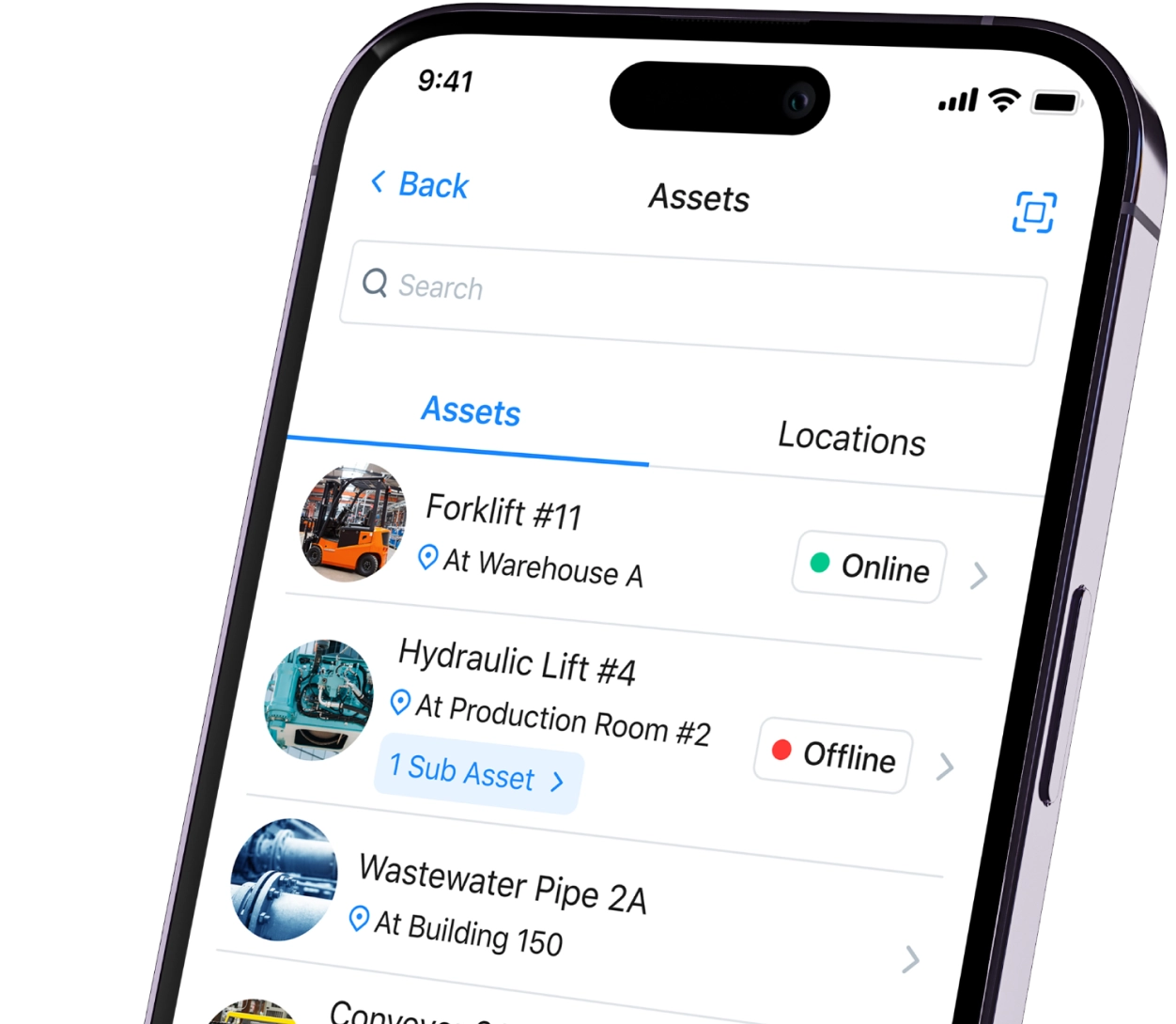
Work order management
Address one-off work requests or schedule work orders in advance from one central system. MaintainX allows you to create, assign, and track work orders in real-time. You’ll be able to keep track of activity across your organization, prioritize work, and share real-time feedback, improving your maintenance operations.
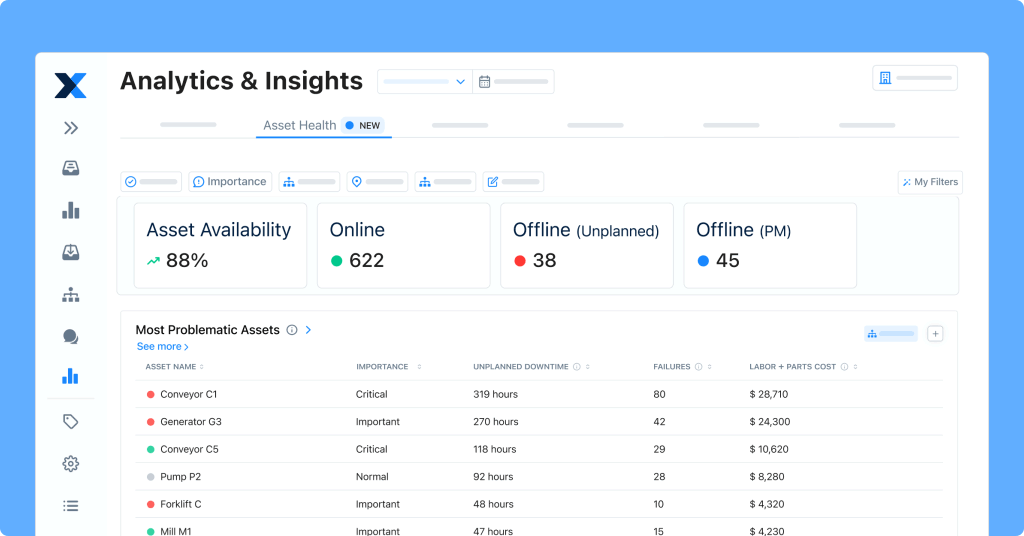
Reporting and analytics
MaintainX’s robust reporting module enables you to create reports to gain insights into your maintenance operations. Use custom dashboards to generate critical insights into your most important metrics. Make data-driven decisions to improve system availability, maintenance, and your operations as a whole.
Don’t settle for good enough. With MaintainX, you won’t just optimize your system availability—you’ll improve all your metrics, empower yourself to take full control of your processes and move your operations to the next level. Book a demo and see how.
System availability FAQs
The levels of system availability include basic availability, high availability, and continuous availability. Basic availability covers standard operational uptime, high availability aims for minimal downtime with redundant systems, and continuous availability strives for virtually no downtime, often using advanced fault-tolerant technologies.
System availability measures the percentage of time an asset is operational and available for use, focusing on uptime and downtime. Asset reliability, on the other hand, assesses how consistently an asset performs its intended function without failure, emphasizing the frequency and impact of breakdowns. System availability is impacted by both planned and unplanned downtimes. However, asset reliability refers to the probability of an asset performing without failure under normal operating conditions for a given period of time—it’s the absence of unplanned downtimes.
Factors affecting system availability include equipment age, maintenance practices, environmental conditions, operational load, and the effectiveness of the monitoring and diagnostic tools used. Human factors, such as operator skill and adherence to maintenance schedules, also play a significant role.
Good system availability typically falls between 98% and 99.9%, indicating that the system is operational and available for use the vast majority of the time. The exact threshold for "good" availability can vary by industry and specific operational requirements. For most manufacturing or industrial settings, an availability rate above 99% is considered excellent. However, the target can vary—highly critical systems, such as those in healthcare or data centers, may require "five nines" availability (99.999%) to ensure minimal downtime.

Caroline Eisner
Caroline Eisner is a writer and editor with experience across the profit and nonprofit sectors, government, education, and financial organizations. She has held leadership positions in K16 institutions and has led large-scale digital projects, interactive websites, and a business writing consultancy.
See MaintainX in action